字符编码的奥秘
谨以本文献给所有被编码问题坑过的程序猿。
起因
前段时间整理散落在各处博文图片,有几个中文文件名的图片要上传,便像平常一样,用 Sublime SFTP 插件直接上传,没想到直接报错了。
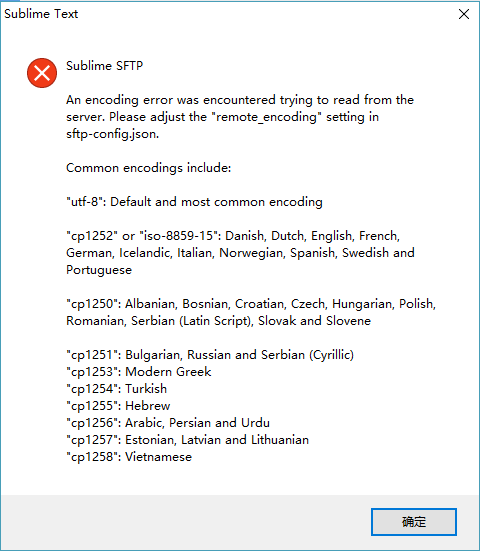
我十分确定服务器上使用的编码是 UTF-8,配置文件也没有错,那到底是什么原因呢,只有看代码了。由于这个插件不开源,只好使用反编译工具 uncompyle6。
debug 过程省略……
最终我找到了引发 bug 的代码,为了方便说明,有修改。
1 | |
经过测试,无论是使用 chcp 65001 还是 set PYTHONIOENCODING=UTF-8 ,locale.getpreferredencoding() 始终返回 cp936……
所以,整理一下,最终出现问题的就是这段了:
1 | |
为什么使用 UTF-8 编码后的文件名再用 CP 936 解码会出错呢?本文就来简单介绍下字符编码的奥秘及其发展简史。
背景
有计算机基础的人可能都知道,文本以二进制形式在计算机中存储和通过通信网络传播的。那怎么把人类可读的文字,转换成机器可以存储和识别的信息呢,于是就有了字符编码。
字符(character)是一段文字的最小单位,它可能是汉字、阿拉伯数字、英文字母、日语假名、标点符号或其他有意义的内容。
字符集(character set)是许多字符的集合,它可能只包含一种语言(比如 ASCII),也可能包含多种语言(比如 Unicode)。
字符编码(character encoding)就是定义和实现把这些字符集的编码成二进制的方式。
很多字符集也定义了对这些字符的编码方案,比如 GB 2112,所以导致有些时候往往将两者混用,对于包含字符有限的简单字符集(一个字符只占用一字节)来说,也没有区分的必要。
ASCII
提到字符编码,就不得不说 ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)。
受电报代码(摩尔斯电码是其中最著名的)的启发,ANSI(American National Standards Institute,美国国家标准学会)的前身——ASA(American Standards Association,美国标准协会)在 1963 年发布了用于计算机及其他通信设备的字符编码标准—— ASCII 的第一版 ASA X3.4-1963。
后来,USASI(United States of America Standards Institute,美利坚合众国标准组织,由 ASA 重组而来)在 1967 年做了一次大更新(主要是控制字符),版本为 USAS X3.4-1967。
ASCII 的最后一次更新是在 1986 年,由 ANSI 发布了 ANSI INCITS 4-1986 (R2012)。
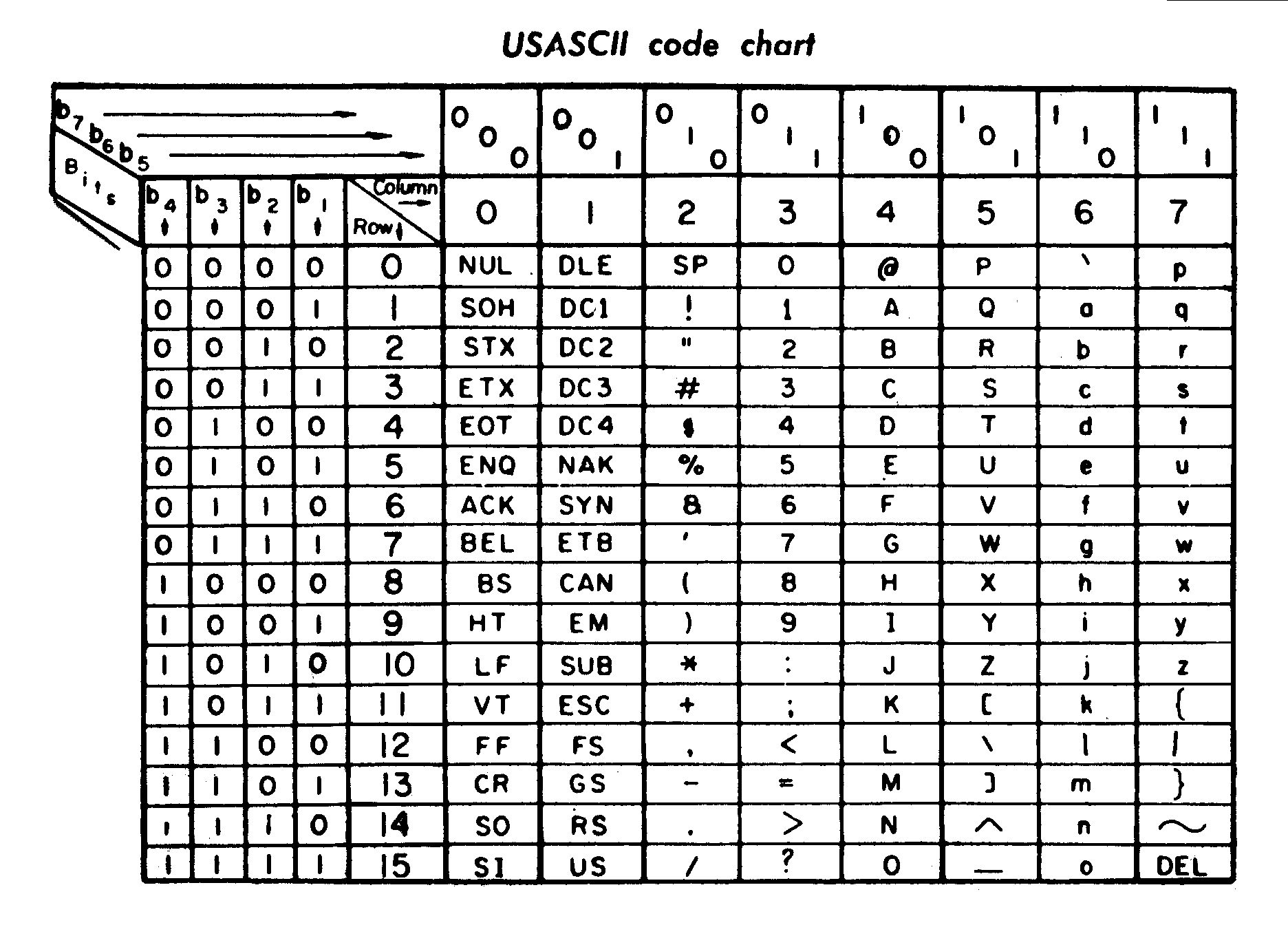
ASCII 编码速见表,来自于一台 1972 年生产的打印机附带的手册
ASCII 是一个典型的简单字符集,只定义了 128 个字符,其中还有 33 个无法显示的控制字符,且大都早已弃用。所以,ASCII 只能用于显示现代英语中的 26 个字母、阿拉伯数字和部分标点符号,但它依旧是影响最深远的字符编码,至今大部分字符编码仍向下兼容 ASCII。
ISO/IEC
ISO(International Organization for Standardization,国际标准化组织)大家都知道,负责制定全世界工商业国际标准的机构,它联合 IEC(International Electrotechnical Commission, 国际电工委员会)制定了一系列字符集/编码标准。
其中最著名的是 ISO/IEC 8859 系列标准(15 个各语言的字符集),在 ASCII 的基础上,(最多)加入 96 个字符,使其能支持当地语言(主要是欧洲)的显示。
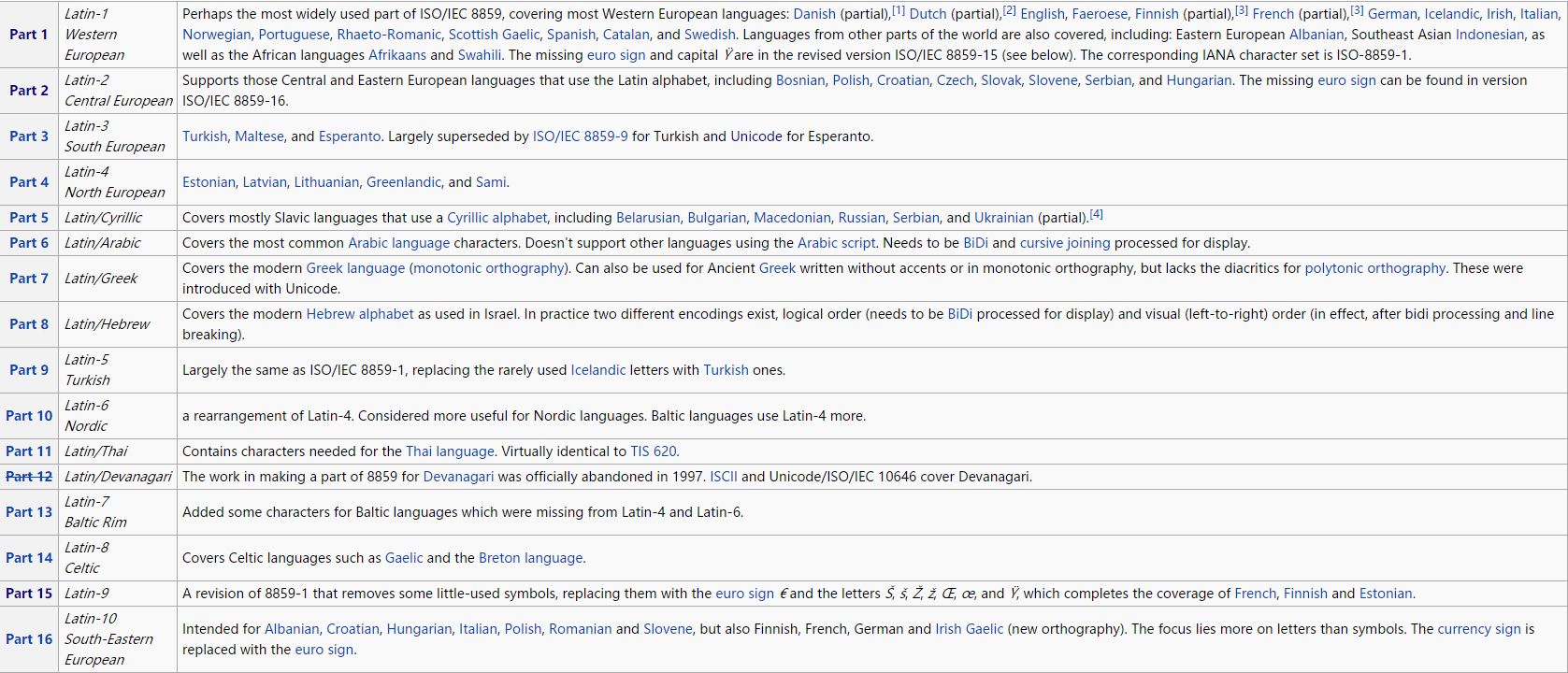
15 个 ISO/IEC 8859 字符集
ISO/IEC 8859 这种给每种语言单独做一套字符集的做法显然不利于国际化,而且与像英语这种由数量有限的字母所组成的音素文字不同,汉语这种语素文字仅常用字就有数千字,简单字符集无法满足。
于是,ISO/IEC 10646,或称 UCS(Universal Coded Character Set,通用字符集)就应运而生。如今,ISO/IEC 8859 不再更新,曾经负责此标准开发的工作组已转而致力于 ISO/IEC 10646 的开发。由于现时的 UCS 与 Unicode 已无太大区别,这里不做过多介绍。
ISO/IEC 8859 和 ISO/IEC 10646 都是字符集,而非编码。由于前者是简单字符集,不需要特殊处理,所以一些软件直接使用 ISO/IEC 8859-X 作为字符编码的名字。另外,也没有单独实现后者的编码,曾经的 UCS-2(for 2-byte Universal Character Set)已被 UTF-16 所取代。
Unicode
当 ISO/IEC 在制定 UCS 的时候,由 Xerox、Apple 等软件制造商于 1988 年组成的统一码联盟(The Unicode Consortium)也在致力于开发一个单一字符集,即 Unicode。1991年前后,两个项目的参与者都认识到,世界不需要两个不兼容的字符集。于是,它们开始合并双方的工作成果,并为创立一个单一字符集而协同工作。
现时,两个项目仍都独立存在,并独立地公布各自的标准。但双方都同意保持两种标准的兼容性,并紧密地共同调整任何未来的扩展。
如今的 Unicode 字符集大致等同于 ISO/IEC 10646,比如 ISO/IEC 10646:2014 plus Amendments 1 and 2,除缺少 Adlam、Newa(均为文字)、日本电视符号和 74 个 emoji 表情外,跟 Unicode 9.0 完全一致。
统一码联盟是一个非营利机构,任何公司、机构或个人只要交保护费会费就能加入。

Unicode 会员
虽然理论上,Unicode 可以从 U+0000 一直定义到 U+FFFFFF(16,777,215 + 1),但是根据 RFC 3629, 只有 U+0000 到 U+10FFFF(1,114,111 + 1)才是可定义的。当然,这些已定义的 code points 还有很多是未赋值的。
尽管 UCS / Unicode 拥有超过一百万个 code points,但在 2000 年之前,大多数系统和软件仍然只支持前 65,536 个 code points,即 BMP(Basic Multilingual Plane,基本多文种平面,U+0000 至 U+FFFF)。直到 2006 年,同样包含一百多万个 code points 的 GB 18030 开始实施,强制要求所有在中国境内发售或使用的所有软件都要支持,这种状况才被改变。

BMP map
Unicode 只是一套字符集,对其编码的实现则称为 UTF(Unicode Transformation Format,Unicode 转换格式)。使用最广泛的 UTF 是 UTF-8(8-bit Unicode Transformation Format)。
UTF-8 使用可变长度的编码,支持一到六字节,128 个 ASCII 字符编码后只占用一字节,汉字大都占用三字节,靠后的字符占用字节要比靠前的多。这样做有什么好处呢?举个简单的例子。
比如要存储小写字母 a,使用 UTF-16 来存储要占用两字节(UTF-16 BE: 00000000 01100001 UTF-16 LE: 01100001 00000000),且总会有一个字节始终为 0x00,这显然很浪费,而用 UTF-8 来存储就只需占用一字节(01100001)。如果只是存储或传输类似一封以现代英语写成的信件的话,UTF-8 就比其他 UTF 更高效。但如果是极少使用的、位于 U+10000 至 U+10FFFF 的字符,使用 UTF-8 编码后就要占用四字节了。
另一种 UTF——UTF-16 还涉及到字节序(Endianness)的问题,即把最低有效位放在最高有效位的前面——小端序(little-endian,LE),还是把最低有效位放在最高有效位的后面——大端序(big-endian,BE)。
“endian”一词来源于乔纳森·斯威夫特的小说《格列佛游记》。小说中,小人国为水煮蛋该从大的一端(Big-End)剥开还是小的一端(Little-End)剥开而争论,争论的双方分别被称为“大端派”和“小端派”。
我下面要告诉你的是,Lilliput 和 Blefuscu 这两大强国在过去36个月里一直在苦战。战争开始是由于以下的原因:我们大家都认为,吃鸡蛋前,原始的方法是打破鸡蛋较大的一端,可是当今皇帝的祖父小时候吃鸡蛋,一次按古法打鸡蛋时碰巧将一个手指弄破了。因此他的父亲,当时的皇帝,就下了一道敕令,命令全体臣民吃鸡蛋时打破鸡蛋较小的一端,违令者重罚。老百姓们对这项命令极其反感。历史告诉我们,由此曾经发生过 6 次叛乱,其中一个皇帝送了命,另一个丢了王位。这些叛乱大多都是由 Blefuscu 的国王大臣们煽动起来的。叛乱平息后,流亡的人总是逃到那个帝国去寻求避难。据估计,先后几次有 11000 人情愿受死也不肯去打破鸡蛋较小的一端。关于这一争端,曾出版过几百本大部著作,不过大端派的书一直是受禁的,法律也规定该派任何人不得做官。
1980 年, Danny Cohen——一位网络协议的早期开发者,在其著名的论文 On Holy Wars and a Plea for Peace 中,为平息一场关于字节该以什么样的顺序传送的争论,而第一次引用了该词。

大端序与小端序
由于字节序的存在,保存文件或传输字符串流的时候,就有必要说明是以什么字节序保存或传输的,BOM(byte-order mark,字节序标记)就是在文件或字符串流开始,用于标识字节序的第一个字符。
UTF-8 没有字节序的问题,UTF-8 with BOM 是微软自己搞出来的,其中的 BOM 仅仅是为了标识该文件使用 UTF-8 编码,某些文本编辑器可能不支持。
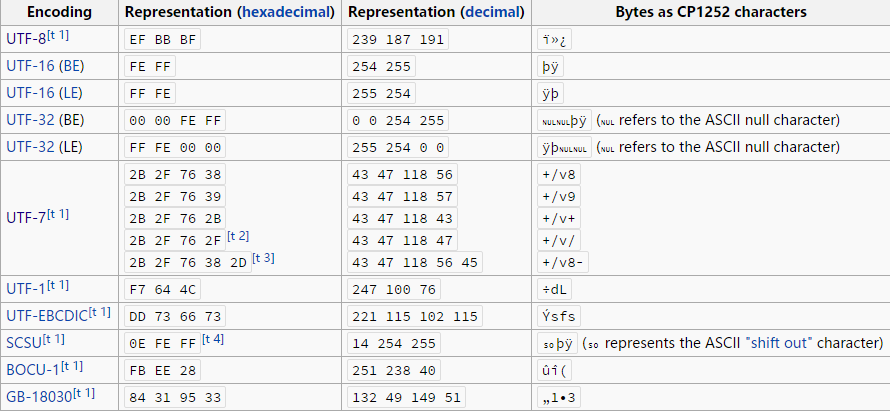
不同编码的 BOM
CJK
受汉语的影响,很多东亚语言都有汉字,但受到本土语言的发展、书写方式的不同、甚至是错别字以讹传讹等影响,各国现时使用的汉字有所出入。各国虽有自己的汉字编码规范,但互不兼容。
为了整合、统一这些汉字,ISO/IEC 和 Unicode 成立了表意文字小组(The Ideographic Rapporteur Group),负责整理“起源相同、本义相同、形状一样或稍异的表意文字”,也就有了中日韩统一表意文字(CJK Unified Ideographs),后来越南文中的喃字也加入了此计划,就合称为中日韩越(CJKV)统一表意文字,可是谁叫你来得晚呢,现在我们仍习惯使用前者。
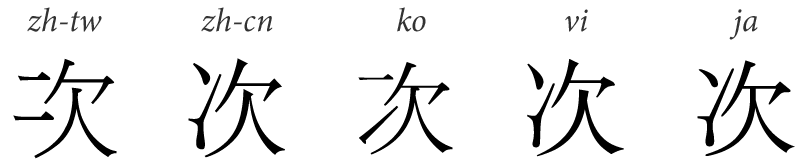
“次”的五种写法
CJK 或 CJKV 实际上是指中日韩(越)现时使用的相同或相近的汉字或其他字符,并非“中日韩统一表意文字”的简称,一些中文资料把 CJK 直接翻译成“中日韩统一表意文字”显然是错误的,而且 Unicode 中不仅仅只包含中日韩统一表意文字,还有其他的 CJK 字符,比如中日韩符号和标点(CJK Symbols and Punctuation)、中日韩笔画(CJK Strokes)等。
GB
说完了国际标准,再来说说国家标准(GB)。GB 2312、GBK 和 GB 18030 是最常见的三个字符集的国家标准,估计很多程序员都分不清它们的关系,我就按照时间顺序来简单介绍下。
GB 2312-80 是中华人民共和国制定的第一套关于简体中文字符集和字符编码的国家标准,全称《信息交换用汉字编码字符集·基本集》,1981 年 5 月 1 日实施。只收录 6763 个汉字和包括拉丁字母、希腊字母、日文平假名及片假名、俄语西里尔字母在内的 682 个字符,基本满足了日常需要。虽已被废弃,但仍有许多软件可以支持。
GBK 全名为《汉字内码扩展规范(GBK)》1.0版,1995 年 12 月制定和公布,属于“技术规范指导性文件”,不属于国家标准。由于 GB 2312-80 收录汉字数量有限,部分简化字、人名(如前总理朱镕基的“镕”字,其实这才是关键)、繁体字及日韩所用汉字并未收录。于是微软利用 GB 2312-80 未使用的编码空间,收录 GB 13000.1-93(等同于 ISO/IEC 10646.1:1993 和 Unicode 1.1)全部字符(共 20,902 个汉字)制定了 GBK。

GBK 编码方式
GB 18030-2005 全称《信息技术 中文编码字符集》,是中华人民共和国现时最新的字符集国家标准,2006 年 5 月 1 日实施,与 GB 2312-80 完全兼容,与 GBK 基本兼容,共收录 70,244 个简繁、日韩汉字和少数民族文字。与 UTF-8 一样都采用可变长度的编码,编码后占用 一、二或四字节。GB 18030-2005 内的单、双字节编码部分,和四字节编码部分收录的中日韩统一表意文字扩展 A 区汉字,为强制性标准,其他部分则属于规范性标准。在中华人民共和国境内发售或使用的所有软件,都需要支持这个同时包含一、二和四字节的编码方式。
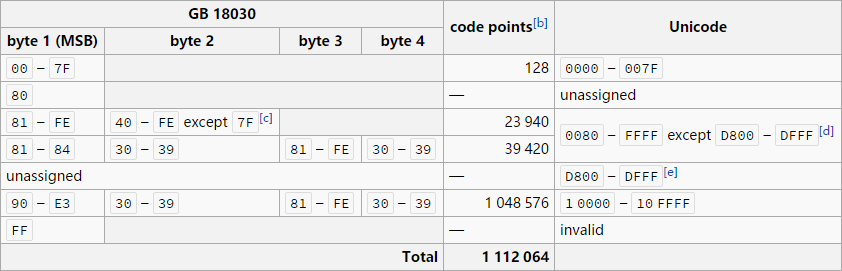
GB 18030 与 Unicode
虽然 GB 18030-2005 已推行多年,但是直到现在,简体中文版 Windows 上 non-Unicode 程序的默认编码仍然是 GBK(CP 936)。
除了大陆政府制定的汉字字符集/编码标准,同时期也有很多汉字编码标准。比如 Big5,流行于港澳台地区等繁体中文地区,但非官方标准,只是业界标准,为繁体中文版 Windows 上 non-Unicode 程序的默认编码(CP 950)。流行于日本地区的 Shift_JIS(CP 932)包含了日语汉字,后来被收录进中日韩统一表意文字。
最早的汉字编码是中文电码(Chinese telegraph code)。1873年,法国驻华人员威基杰参照《康熙字典》的部首排列方法,挑选了常用汉字6800多个,编成了第一部汉字电码本《电报新书》。中文电码表采用了四位阿拉伯数字作代号,从 0001 到 9999 按四位数顺序排列,用四位数字表示最多一万个汉字、字母和符号。
Windows Code Pages
除了 UTF-8、UTF-16 等通用字符编码,还有很多区域性的字符编码。Windows 作为一个在全球发售的操作系统,自然也要支持,于是就有了 Windows code pages(Windows 代码页)——一份 MicroSoft Windows 所兼容的字符编码列表,及其在 Windows 中的别名。
因为微软最初是给 IBM 做 MS-DOS(其 IBM PC 专用版本为 PC-DOS,两者差异不大)系统起家的,所以 Windows code pages 实际上是继承于 IBM PC / DOS (OEM) code pages,包括 CP 936。
Windows code pages 微软以前称之为 ANSI code pages,为什么改名呢?
Windows code pages 中的第一个(非继承自 OEM code pages)——1252(Windows West European Latin 1)确实是根据 ANSI 的草案(即后来成为 ISO 标准的 ISO/IEC 8859-1,更为人所知的别名是 Latin-1 或“西欧语言”)制定的,但是后面的 code pages 就不是了。用了一段时间后,微软才发现自己用错术语,于是就改名了。可惜用得太久了,很多地方仍保留着错误的旧名字。至今,如果你打开记事本、选择另存为仍能看到 ANSI。
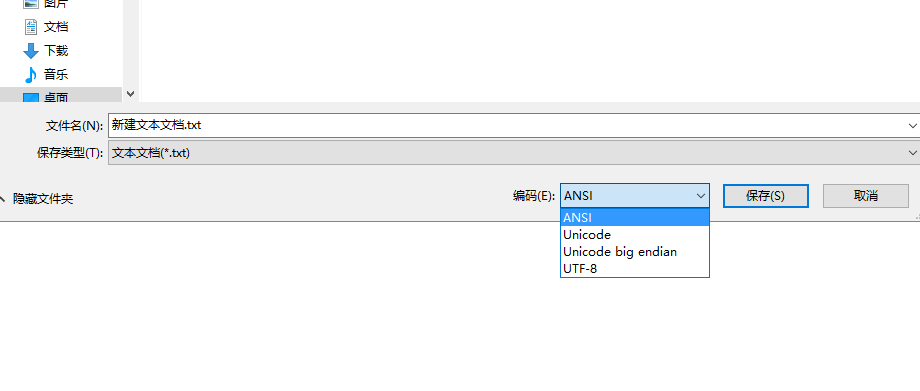
另存为“ANSI”编码
Windows NT 内核虽早已支持 Unicode,但 CMD(命令提示符)和 PowerShell 并不(完全)支持,默认字符集不是 Unicode。
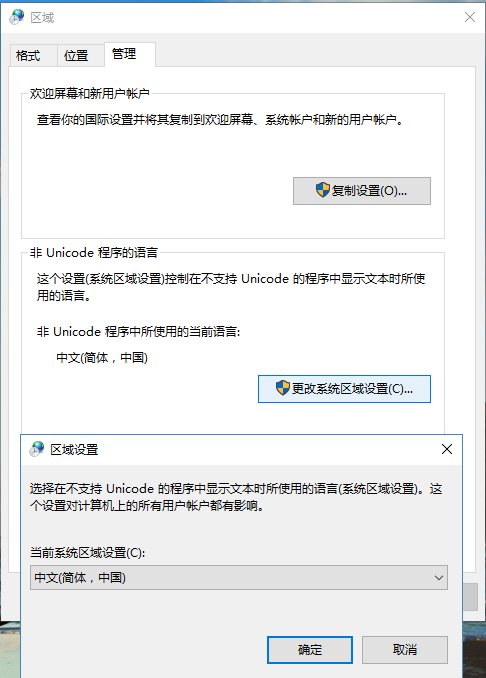
修改 Windows 上 non-Unicode 程序的默认编码
前面我提到过,CP 936 是简体中文版 Windows 上 non-Unicode 程序的默认编码,其最初版本和 GB 2312 一模一样,后来在推出 Windows 95 时增加了绝大部分 GBK 中的字符。
虽然 CP 936 通常被视为等同于 GBK,连 IANA(Internet Assigned Numbers Authority,互联网号码分配局)也视 CP936 为 GBK 的别名。但相比较一下,GBK 比 CP 936 多定义了 95 个字符(15 个非汉字及 80 个汉字),都是当时未收录进 UCS / Unicode 的字符。虽然新版 Unicode 早已收录这些字符,但 CP 936 至今未修订。
GB 18030 所对应的 Code Page 为 54936,从 Windows XP 起开始加入,但实际并未完全支持。不过由于 GB 18030 向下兼容 GBK,所以大部分情况下并无问题。至于原因,北大中文论坛有相关讨论。
Python Standard Encodings
Python 作为一个跨平台的语言,自然也要维护一套自己支持的编码列表,以适应各种(非)官方的别名及 code pages,于是就有了下表。
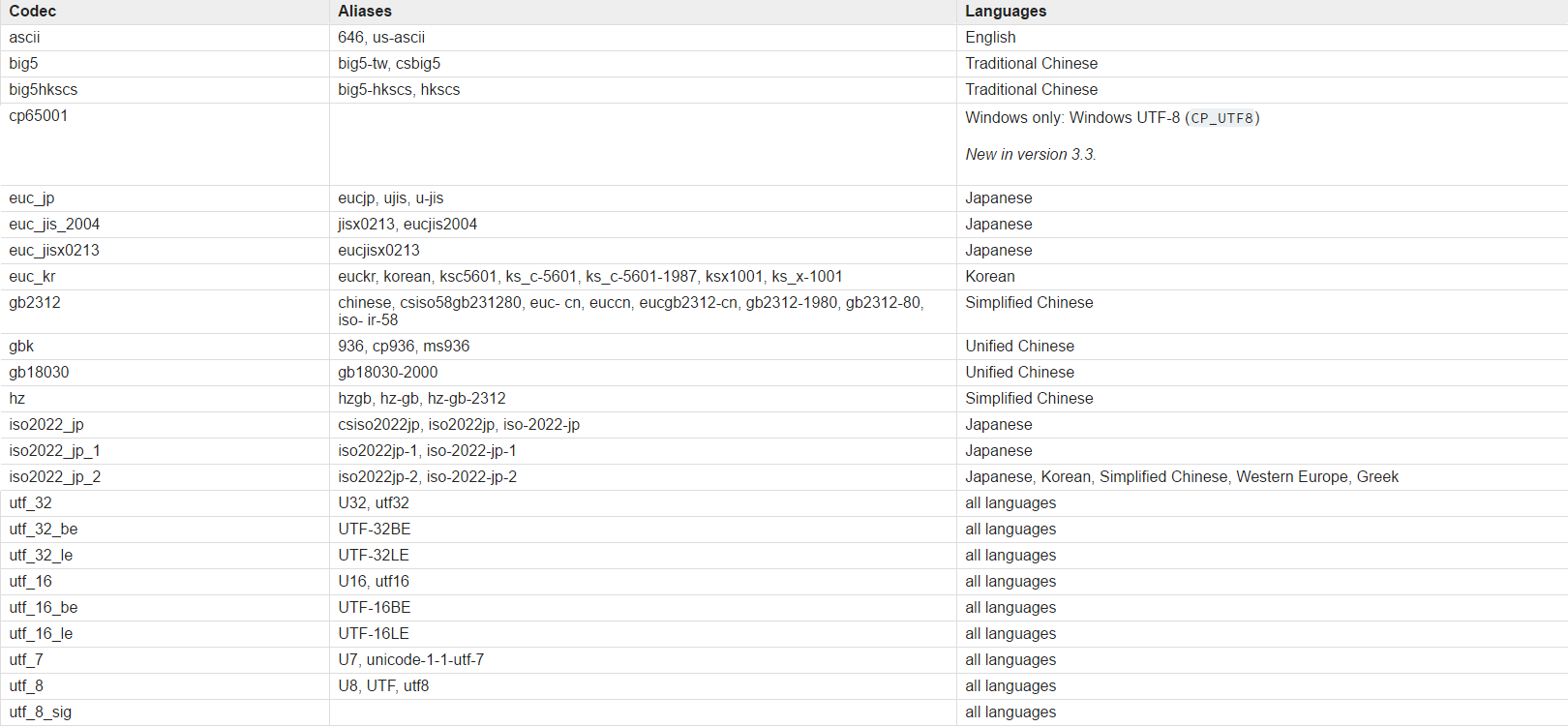
Python Standard Encodings(节选)
其中 Unified Chinese 应该是 Python 作者自己搞出来的名字,我搜索不到任何结果,就字面意思来看,应该是包含简繁的中文编码。
Python 支持 GB 18030,更具体点是 GB 18030-2000,但不支持所对应的 Windows Code Page 54936。
结语
最后,当我们回过头来看最初的问题,答案就很简单了。
因为作者使用命令(CMD)而不是 API 调用第三方软件,但 CMD 默认字符集不是 Unicode,而且远端的服务器也不一定是用 Unicode 编码,所以作者想出了这么蛋疼的方法去转码,以保证文件名不会出现乱码。
由于很多编码都向下兼容于 ASCII(128 个 ASCII 字符编码一致,包括 UTF-8、GBK 和 GB 18030 等),所以如果是仅仅使用编码后仅占用单字节的现代英语作为文件名,很难发现这个问题,结果这个 bug 就隐藏了这么久。
那么在服务端仍使用 UTF-8 的情况下,我们用向下兼容于 GBK、code range 又与 Unicode 相似的 GB 18030 替换 GBK 能解决这个问题吗?
这是一道陷阱题,回答“可以”的同学请回顾前面关于 UTF-8 和 GB 18030 的相关内容。code range 指的是字符集所能定义的范围,对比对象是 GB 18030 与 Unicode 这两个字符集,跟 UTF-8 这个字符编码没有关系。
UTF-8 支持一到八字节,而 GB 10830 只支持 一、二、四字节,还要考虑每个字节的范围,肯定不兼容。汉字使用 UTF-8 编码后,大都占用三字节,比如“的”字(U+7684),编码后的 hex 为 E7 9A 84。
You should NEVER EVER decode an encoded string by using an unmatched encoding.
虽然 Unicode 在某些字符上有错误,很多生僻字甚至是小语种都没有收录,但它是目前在全世界范围内最通用的字符集,而且还在不断更新(最新一版是 2016年6月21日 发布的 9.0.0),UTF-8 则是其最受欢迎的一种编码实现方式。所以我的看法是:在没有特殊需求的情况下,
请使用 UTF-8 (without BOM)!
相关资料
- 相关中英文维基百科,链接太多,不一一放出
- Unicode 9.0 Character Code Charts
- Unicode Frequently Asked Questions
- Unicode character table
- MicroSoft Code Page Identifiers
- Windows Best Fit
- MSDN - Glossary of Terms Used on this Site
- Python Standard Encodings